Digital Health Outcomes Blog
Digital Health Outcomes exhibiting at ISPOR Europe 2025

Want to learn how digitized health economic models can help to communicate value? Meet the Digital Health Outcomes and Global Market Access Solutions teams at ISPOR Europe. We are exhibiting at booth #520 in front of… Read more ![]()
AMCP eModel Hub launched at AMCP 2025 meeting
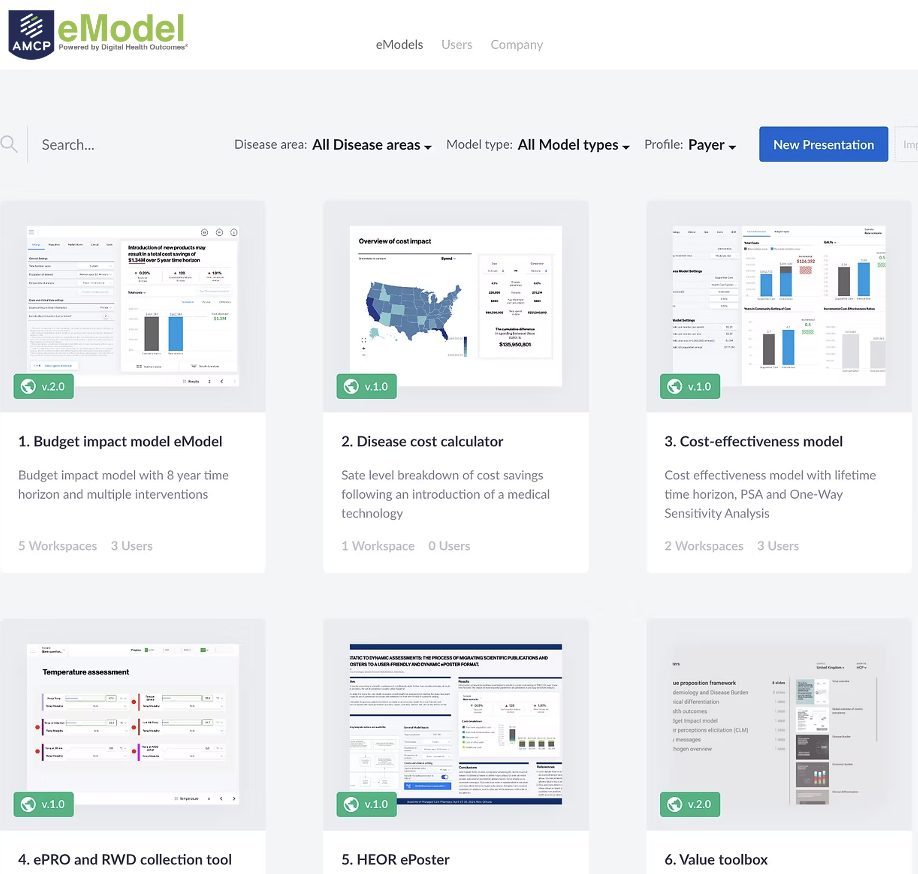
We are pleased to announce the launch of AMCP eModel Hub – a central repository for health economic models, ePosters and evidence data tools The hub allows users to: perform live simulations of expected health and… Read more ![]()
The Academy of Managed Care Pharmacy (AMCP) and Digital Health Outcomes are pleased to announce a strategic partnership on AMCP eModel.

During the meeting we are introducing AMCP eModel – a new framework to improve utility, transparency and usefulness of health economic models. “The Academy of Managed Care Pharmacy (AMCP) and Digital Health Outcomes (DHO) are pleased… Read more ![]()
Meet Digital Health Outcomes and Global Market Access Solutions at ISPOR Europe 2023

The Digital Health Outcomes Team will be attending ISPOR Europe 2023 in Copenhagen. We are looking forward to meet old friends and explore new connections! If you’d like to meet and understand how Digital Health Outcomes… Read more ![]()
Much faster probabilistic sensitivity analysis (PSA) with cloud based horizontal autoscaling
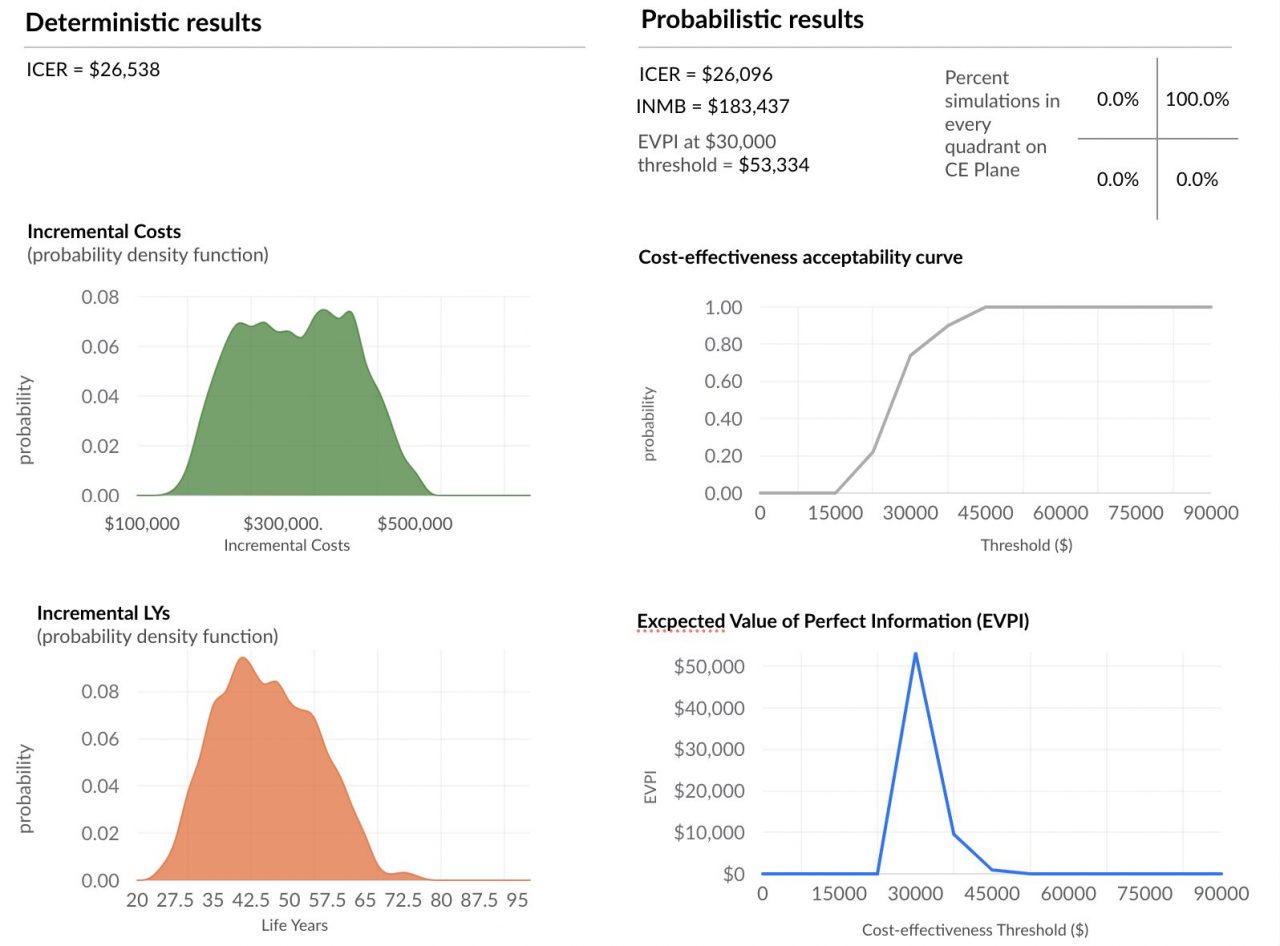
Background and definitions: Decision-makers require estimates of decision uncertainty alongside expected net benefits (NB) of interventions. This requirement may be difficult in computationally expensive models, for example, those employing patient level simulation[1]. Probabilistic sensitivity analysis (PSA) is… Read more ![]()
Interactive health data visualization approaches: good practices and examples

How interactive data visualizations change communication of health data Presentation of health data is undergoing a big change, one that will influence not only how payers and providers make their decisions but also how pharma, medical… Read more ![]()
Automatic Data Sourcing for Health Economic Models – Interoperable data for timely decision-making
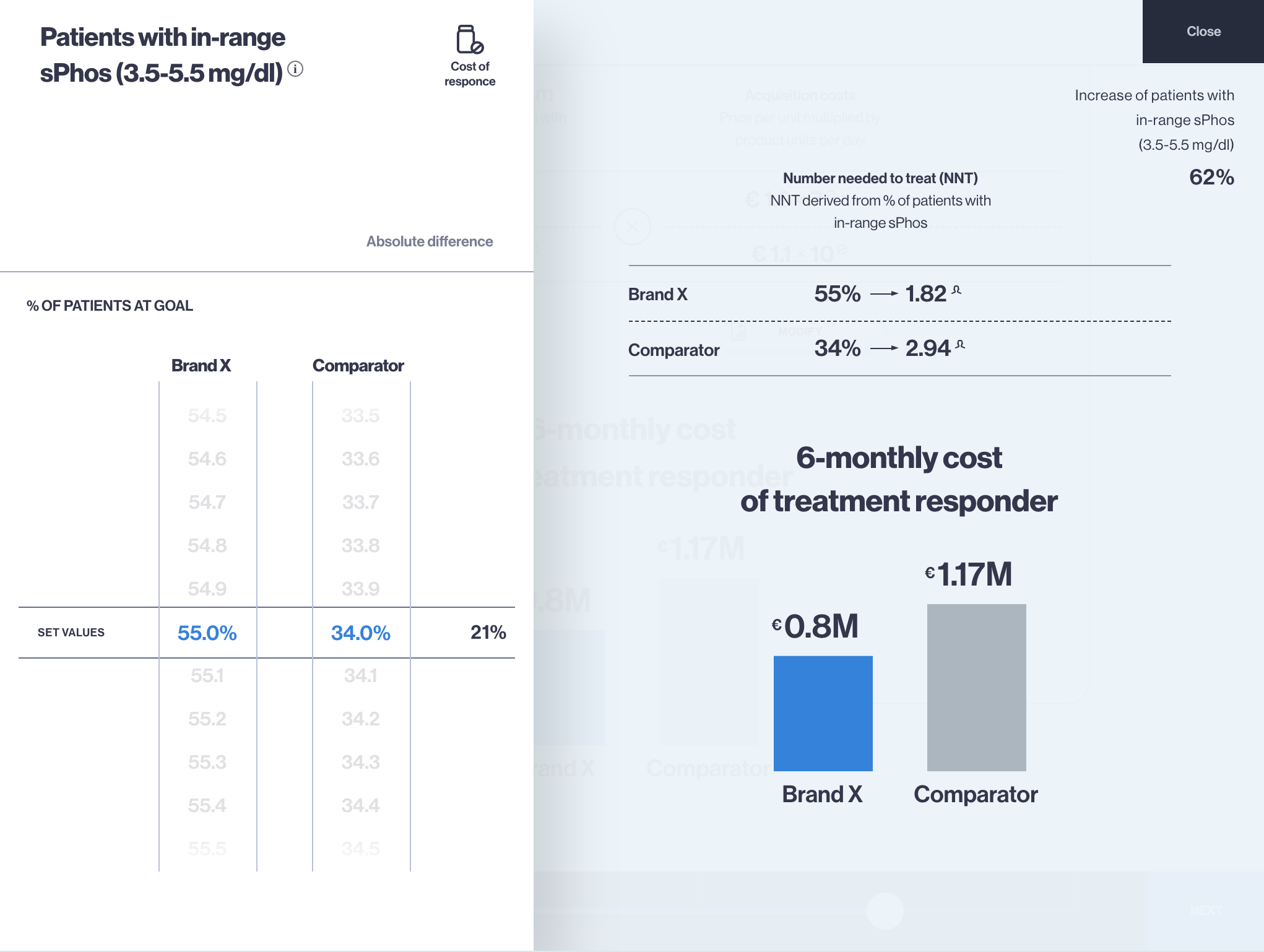
This article is inspired by the exciting idea of data interoperability in health economics modelling process, which means sourcing (fetching) inputs for models in real-time, using modern software infrastructure capabilities. On a larger scale, development of… Read more ![]()
Digital Health Outcomes launched interactive health economic modeling platform together with the Institute for Clinical and Economic review (ICER).
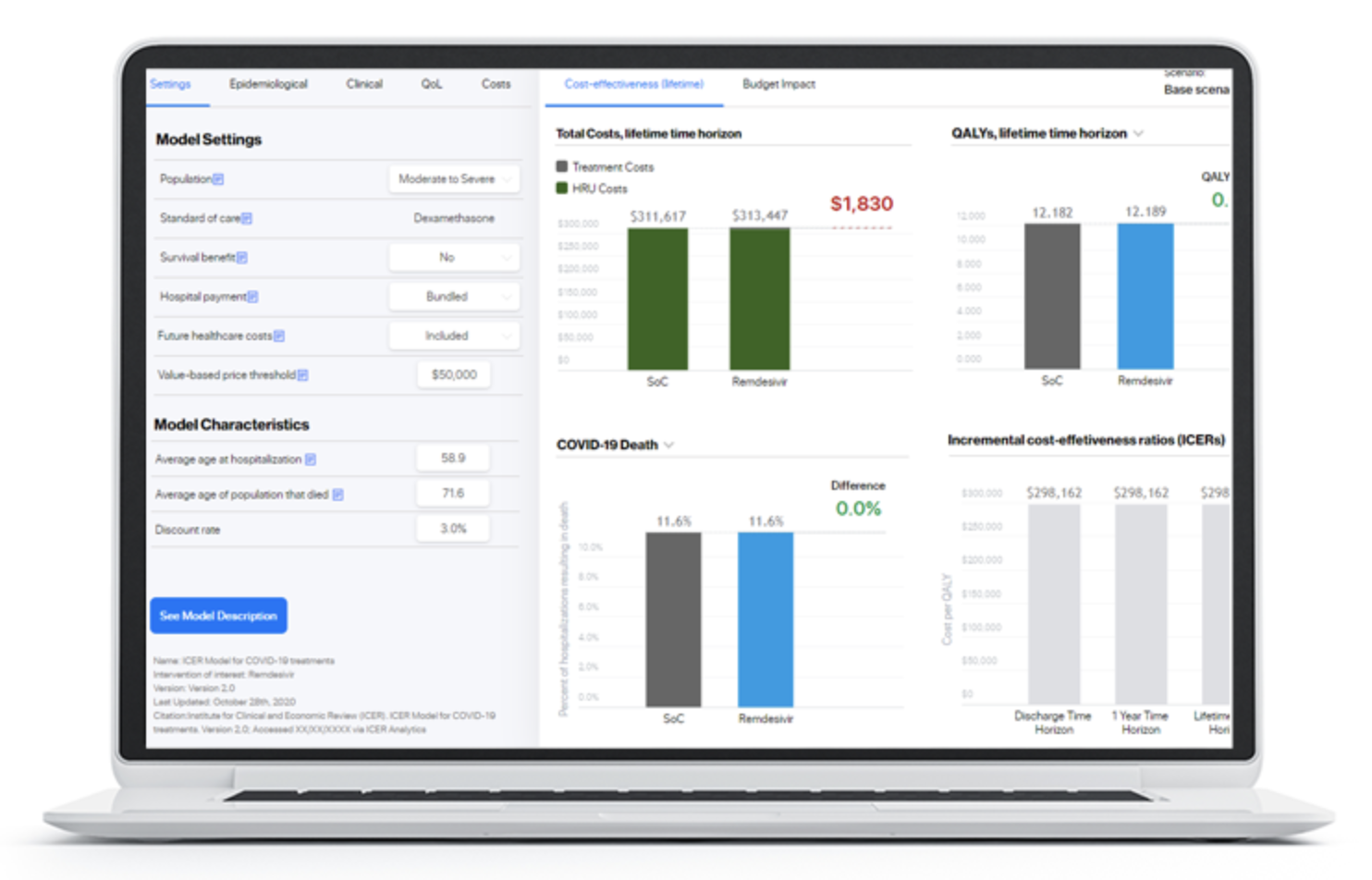
We are delighted to support the US based Institute for Clinical and Economic (ICER) in launching a dedicated interactive modeling platform hosting a wide variety of cost-effectiveness and budget impact models developed by ICER and their… Read more ![]()
Budget Impact Model app for iPad and Web – an effective tool for payer engagement
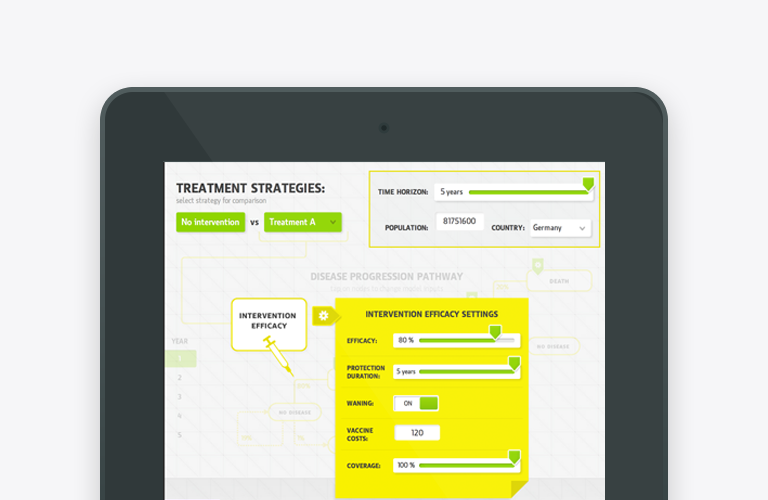
Budget Impact Model (BIM) is the health economics type of model which calculates the net cost of including a new drug or therapy into certain healthcare system or payer, hospital settings. Budget impact model app (budget… Read more ![]()
Systematic Review and Meta-Analysis — Overview
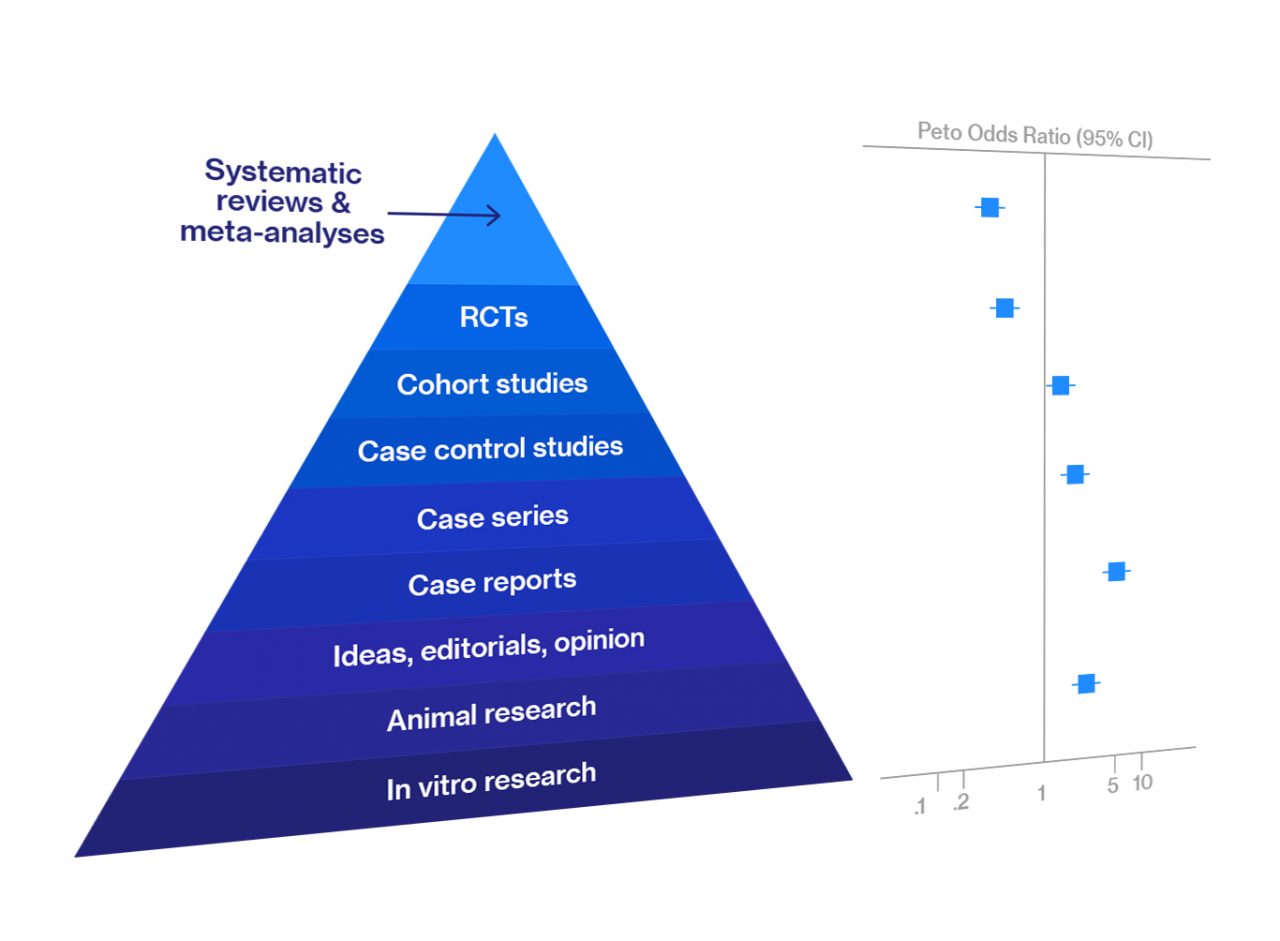
Meta-analysis and systematic review are at the top of the hierarchy of evidence for data reliability in various types of biomedical research. They are an integral part of evidence-based medicine. Most clinicians begin searching for the best, evidence-based… Read more ![]()
