News
The Academy of Managed Care Pharmacy (AMCP) and Digital Health Outcomes are pleased to announce a strategic partnership on AMCP eModel.

During the meeting we are introducing AMCP eModel – a new framework to improve utility, transparency and usefulness of health economic models. “The Academy of Managed Care Pharmacy (AMCP) and Digital Health Outcomes (DHO) are pleased… Read more ![]()
Meet Digital Health Outcomes and Global Market Access Solutions at ISPOR Europe 2023

The Digital Health Outcomes Team will be attending ISPOR Europe 2023 in Copenhagen. We are looking forward to meet old friends and explore new connections! If you’d like to meet and understand how Digital Health Outcomes… Read more ![]()
mClinical Research – compliant mobile applications that fit each study protocol
Mobile apps and study portals with CFR 21 Part 11 compliance, infrastructure, and process, developed specifically for the biopharma R&D organisation. Meet us at ISPOR in Boston to learn more about our mClinical Research software and… Read more ![]()
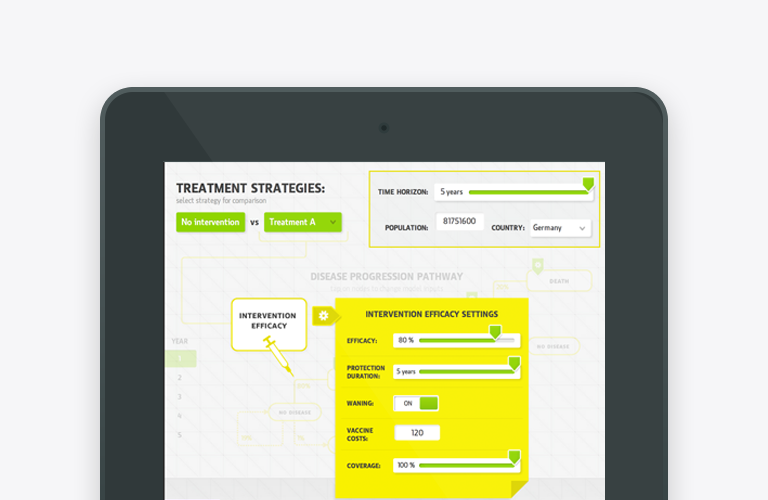
We are announcing eModels Platform – the new end-to-end solution for health economic models digitisation and communication
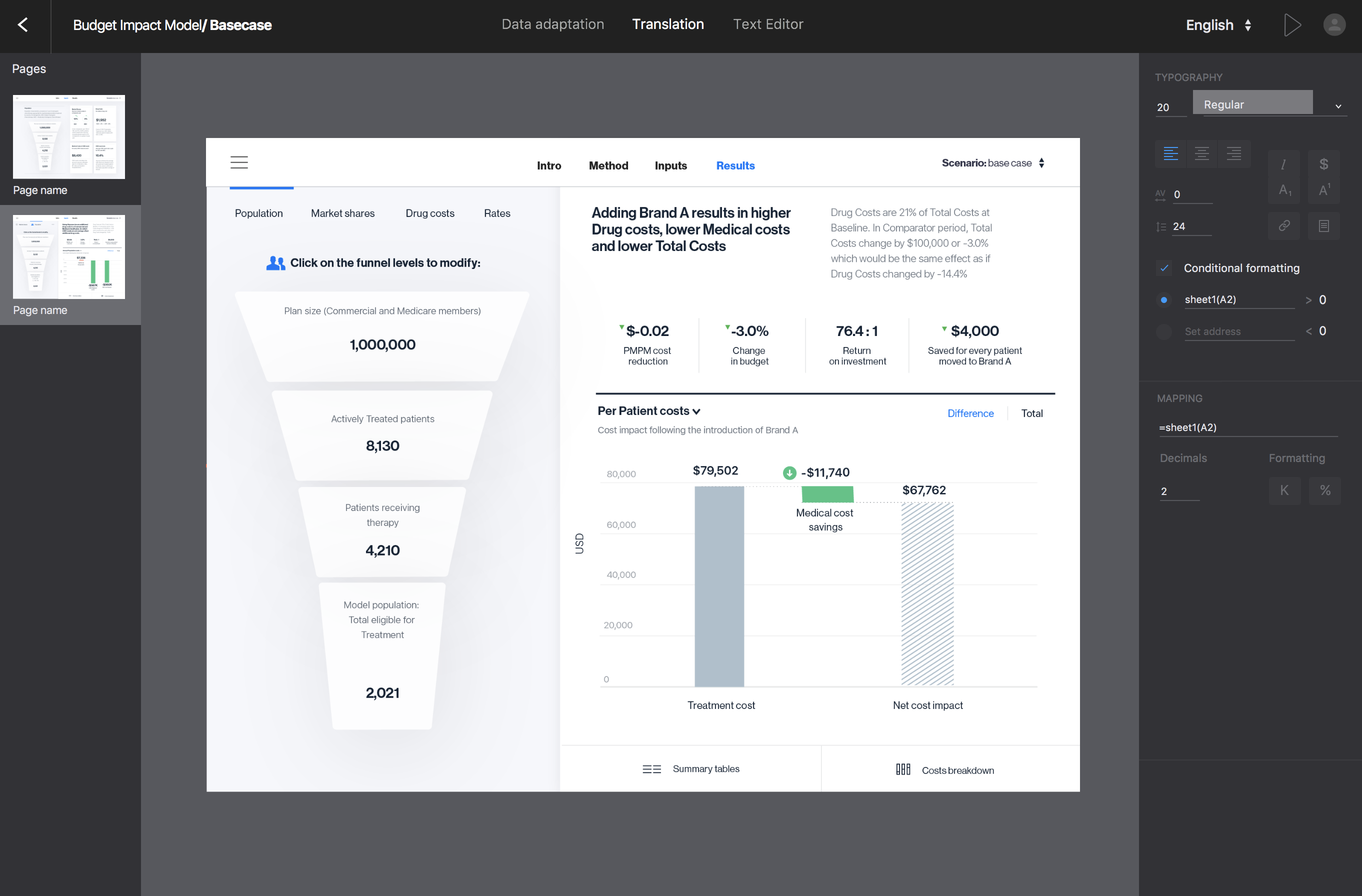
It has taken us some quite years to develop and release our new eModels Platform for health economics models (cost-effectiveness, budget impact) and global value dossiers (GVD) creation, adaptation and value communications. This new integrated solution… Read more ![]()
Meet Digital Health Outcomes and Global Market Access Solutions at ISPOR in Copenhagen

We are delighted to continue our ongoing participation at ISPOR as exhibitors and short-course instructors. Join our booth (C4-091) to learn more about our innovative technology solutions for value evidence communication and data collection. We’d be… Read more ![]()
Digital Health Outcomes exhibiting at ISPOR in New Orleans

This year at ISPOR our team of health economists and software specialists will be presenting new solutions developed to accelerate market access and research. We are proud to present our eModels builder platform designed to scale… Read more ![]()
Digital Health Outcomes and GMAS at ISPOR in Barcelona

Join our booth number 215 to learn more about the digital tools and alternative approaches to express healthcare value. We are exhibiting with our partner company Global Market Access Solutions (GMAS) and jointly running a short… Read more ![]()
Digital Health Outcomes at ISPOR in Glasgow

Join our booth number 111 to learn more about the innovative digital tools for health economics and market access. This year we are exhibiting at ISPOR together with our partner company Global Market Access Solutions (GMAS)… Read more ![]()
Digital Health Outcomes exhibiting at ISPOR in Boston, MA

Please pass by our Digital Health Outcomes booth #415 to speak about approaches to accelerating digital transformation in your organisation. Our team of experts will be presenting market access support platforms, interactive health economics models, value… Read more ![]()
Digital Health Outcomes at ISPOR 19th Annual European Congress

Interested to learn more about interactive health data visualizations, digital tools and communication interfaces for HEOR models ? We welcome ISPOR participants to meet us at our booth #512. We will be presentation our latest works,… Read more ![]()