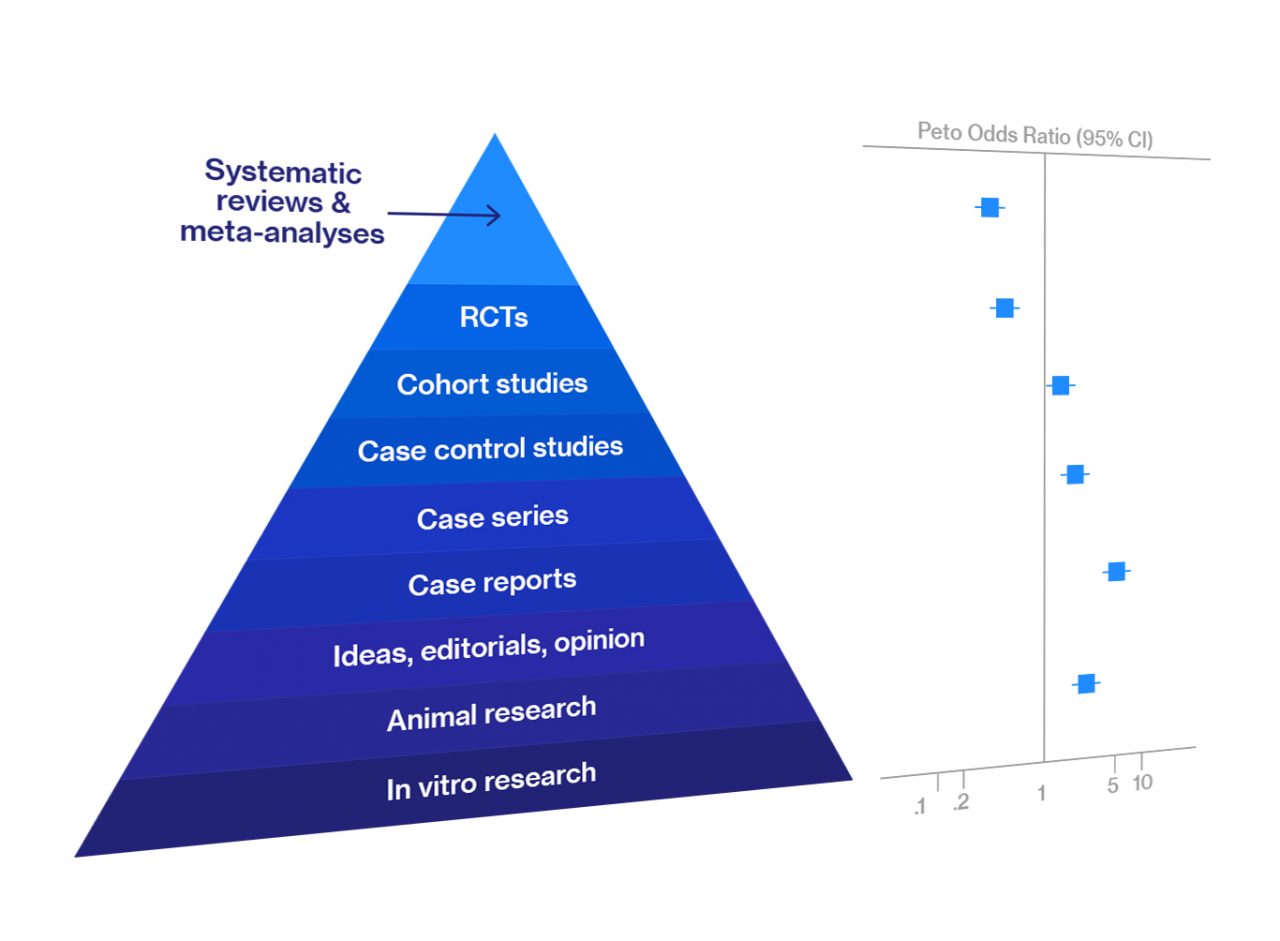
Background and definitions: Decision-makers require estimates of decision uncertainty alongside expected net benefits (NB) of interventions. This requirement may be difficult in computationally expensive models, for example, those employing patient level simulation[1].
Probabilistic sensitivity analysis (PSA) is a technique used in economic modelling that allows the modeller to quantify the level of confidence in the output of the analysis, in relation to uncertainty in the model inputs. There is usually uncertainty associated with input parameter values of an economic model, which may have been derived from clinical trials, observational studies or in some cases expert opinion. In the base case analysis, the point estimate of each input parameter value is used.[2]
Microsoft Excel is currently the most commonly used software tool for developing health economic models as it is a flexible resource that can be accessed and understood by a very wide audience.
Problem: Often to run Probabilistic Sensitivity Analysis users rely on local computers with limited number of RAM and CPU. Indeed, MS Excel is optimised for multicore tasks, but some issues with performance were reported[3].
Now lot’s have a look at what it would take to run Expected Value of Perfect Information (EVPI) analysis or conditional PSA. In every PSA run each parameter hold constant, whilst all others are varied. With such approach we calculate the impact of removing each parameter on sample variance. To run analysis for 200 model input parameters it would require: 200 inputs * 1,000 iterations = 200,000 individual simulations. If Excel model consists of a Markov trace with weekly or daily cycles and multiple health states, such analysis may take days or weeks to complete.
Solution: So how can we optimise computational speed of each PSA iteration and complete the 200K run much faster? Cloud computing and so called horizontal and vertical scaling can help. Let’s have a closer look at horizontal and vertical scaling.
As defined by Amazon Web Services (AWS) – A “horizontally scalable” system is one that can increase capacity by adding more computers to the system. This is in contrast to a “vertically scalable” system, which is constrained to running its processes on only one computer; in such systems the only way to increase performance is to add more resources into one computer in the form of faster (or more) CPUs, memory or storage. Horizontally scalable systems are oftentimes able to outperform vertically scalable systems by enabling parallel execution of workloads and distributing those across many different computers.
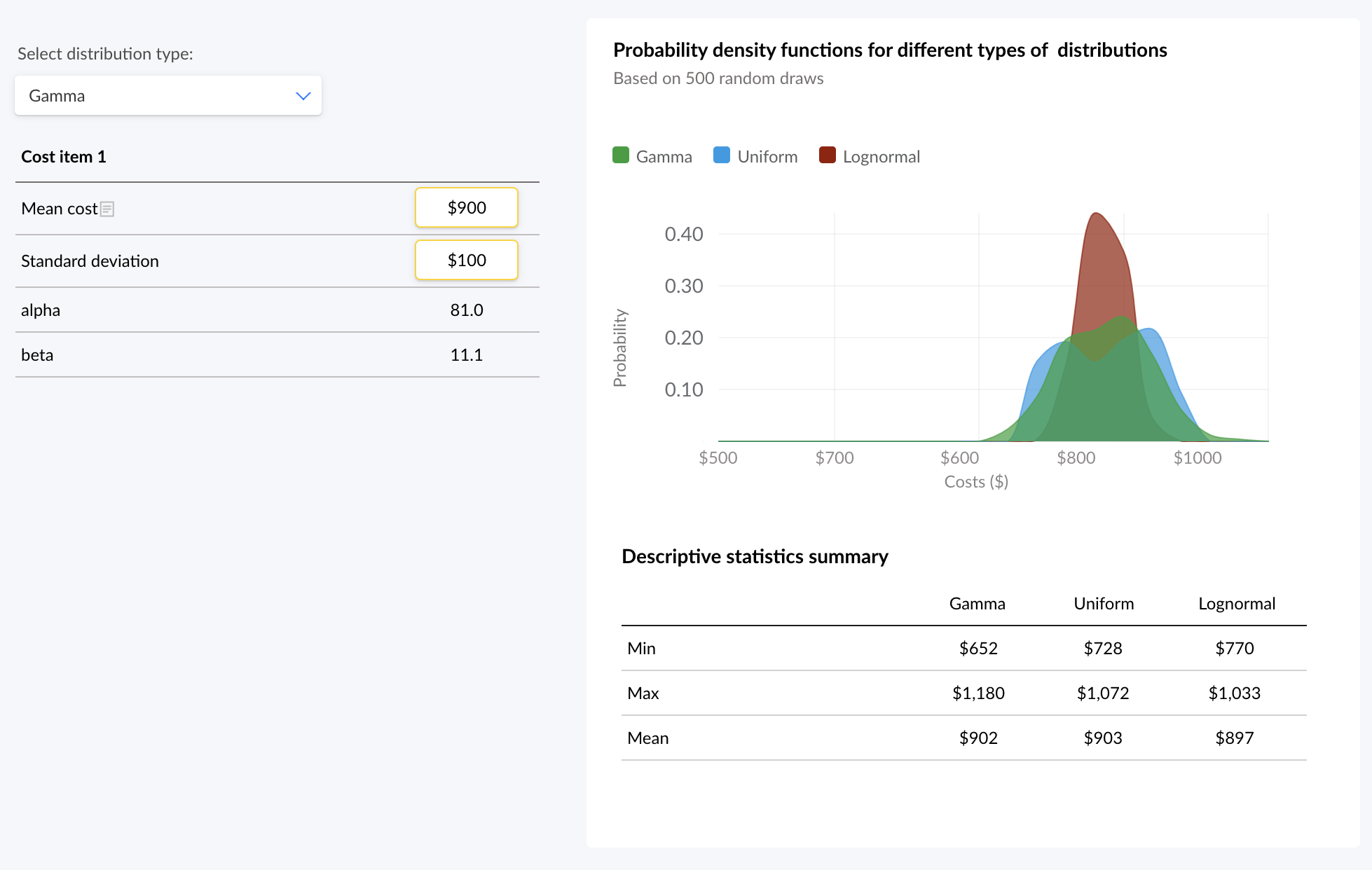
Results: Several distribution types including Beta, Gamma and Lognormal were used to run the analysis. The selection of these distribution types impact probabilistic parameter values obtained as inputs and results in PSA. Figure 1 presents the difference in probability density function for each of the 3 distribution types. For example Lognormal distribution leads to higher chance of getting values that are closer to mean.
Figure 1: Probability density function for various distribution types
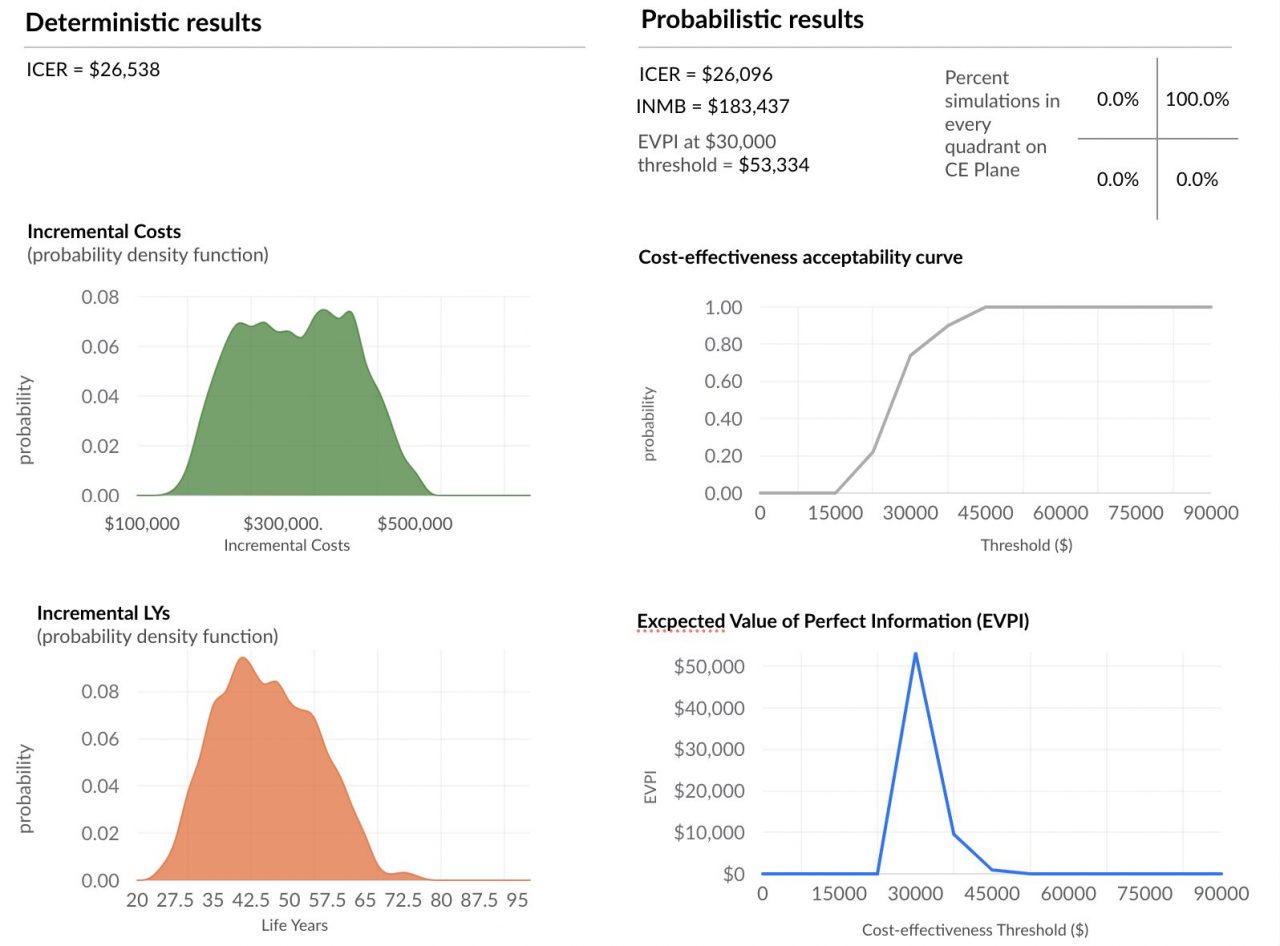
We have transformed an existing health economic model initially developed in Excel into a low level code object that can be executed in the cloud (server on AWS). Firstly, the new model object ran faster than original Excel package. PSA results are presented in Figure 2.
Figure 2. Results of Probabilistic Sensitivity Analysis in Health Economic model. Number of iterations = 1,000
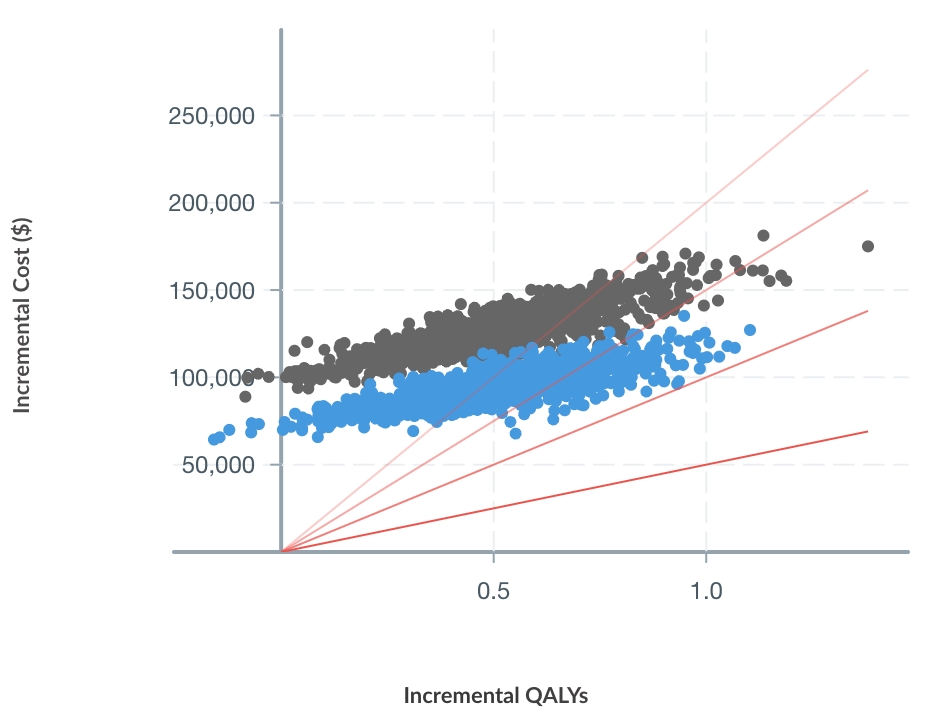
Secondly, the proposed horizontal scaling method substantial decreases calculation speed with ~98.% reduction in waiting time.
Time required to run health economic model having 3 interventions, weekly cycles and 32 health states. Both costs and QALYs are calculated:
- 8 CPU local Windows machine: 16.7 hours
- 64 CPU: 1.02 hours
- 192 CPU: 21 minutes
Also, cloud based PSA doesn’t block the thread, meaning that one can still use and navigate model file on the same machine.
Conclusions: With horizontal autoscaling we can now concentrate on what matter the most (finding new research questions), rather then getting stuck waiting for the answer to current research question.
References:
- Griffin, S., Claxton, K., Hawkins, N., & Sculpher, M. (2006). Probabilistic analysis and computationally expensive models: Necessary and required?. Value in health : the journal of the International Society for Pharmacoeconomics and Outcomes Research, 9(4), 244–252. https://doi.org/10.1111/j.1524-4733.2006.00107.x
- Probabilistic/Stochastic Sensitivity Analysis [online]. (2016). York; York Health Economics Consortium; 2016. https://yhec.co.uk/glossary/probabilistic-stochastic-sensitivity-analysis/
- Microsoft. https://answers.microsoft.com/en-us/msoffice/forum/all/how-to-utilize-multiple-cores-in-excel-2016/76fef7bb-750d-42f7-95ca-91d2694479c1